JapanLLMでは日本および世界のLLM(大規模言語モデル)や生成AIについて研究・調査を行った結果を発表していきます。またLLMの実用例としてすでに普及しているプログラミング支援機能(Code Complete, Code Generation)などについても記事を載せていきます。
Table of contents
Open Table of contents
LLMは人間の脳のモデル化
2017年に”Attention is all you need”という論文で発表されたトランスフォーマーとよばれる大規模言語モデルは人間の脳をモデリングしたAI技術の一つです。
2017年以前はCNN(畳み込みニューラルネットワーク)やRNN(リカレントニューラルネットワーク)といった技術が主流でした。自然言語の翻訳などでCNNやRNNは用いられ機械翻訳の手法の一つとして成果を上げていました。
しかし,CNNやRNNは致命的な欠点が一つありました。
それは,自然言語などの「単語の順番」が重要な意味を持つデータに対して,シーケンシャルに前から順に処理していく必要があったという点です。前から順に処理していく必要があるということは並列化しにくいということを意味しており,学習効率が低く,データが大規模になるとその学習には膨大な時間を要しました。つまり,モデルを学習させるのに膨大な時間とコストがかかっていたのです。
2017年のトランスフォーマーの発表で状況は一変しました。
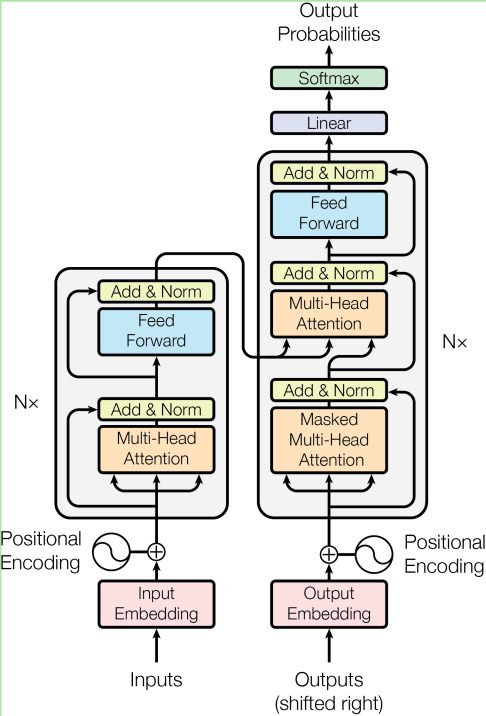
トランスフォーマーは”Multi-Head Attention”, “Self-Attention”, “Masked Multi-Head Attention”といったアテンションという仕組みを導入しました。これは言語処理の例で言えば,ある単語と別の単語の関連性の強さを数値化し行列で表したものです。この関連性の強さを計算する方法として同時に複数の単語との結びつきの強さを並列計算できるようにしたのが,“Multi-Head Attension”(多頭アテンション)技術です。たとえば,MetaのLlama3.1などのモデルではこのMulti-Headの数は8個となっています。
アテンション計算で学習する
左半分が学習, 右半分がプロンプトに対する思考と回答
Attentionの計算にはクエリ(Query), キー(key)という2つの入力と, 値(Value)という出力の合計三要素があります。
クエリ:単語A キー:単語B 値:単語Aと単語Bの関連性の強さ
このクエリ・キーからバリューを算出する作業がLLMの事前学習・回答生成作業の大半を占めます。このアテンションの計算で得られるバリューは行列になっており,単語と単語の相関性の強さを表すことができます。
LLMの事前学習では”Self-Attention”という技術が用いられます。
- 入力したデータの内部の単語同士の関連性を片っ端から計算する
- すべての単語間の相関性を-1から1までの間の浮動小数に正規化する
- 上記の正規化した行列を格納する
簡単に言うと最終的に得られた行列こそが事前学習結果そのもの。学習済みの「脳」です。
アテンション計算で学習する
この”Self-Attention”はエンコードとも呼ばれます。最初に示したトランスフォーマーの図で言うと左半分の部分がエンコード処理(事前学習),そして右半分の部分がデコード処理(プロンプトに対する思考と回答)と言い換えることができます。
トランスフォーマーはこのように学習工程(左半分のエンコード処理)で”Self-Attention”を用いて膨大なデータから効率的に学習を行い現在では1000Bクラス(1超個)の巨大な言語モデルも登場しています。インターネット上から得られるほぼすべてのデータを学習し尽くすのも時間の問題でしょう。
トランスフォーマーがRNNなどの従来技術と比較して画期的だったのは,このアテンションと呼ばれる単語間の関連度を並列計算できるようにした点です。
アテンションの計算は単語の並びとは全く独立に計算することができ,その結果GPUなどの並列計算機を用いることで効率的に大規模なデータを学習させLLM(大規模言語モデル)を強化することができるようになりました。
LLMの学習工程
学習工程はまず単語の並びを把握することから始まります。 下図左下のPositional Encodingが入力された学習データを単語の並びを意味する行列に換算する処理です。
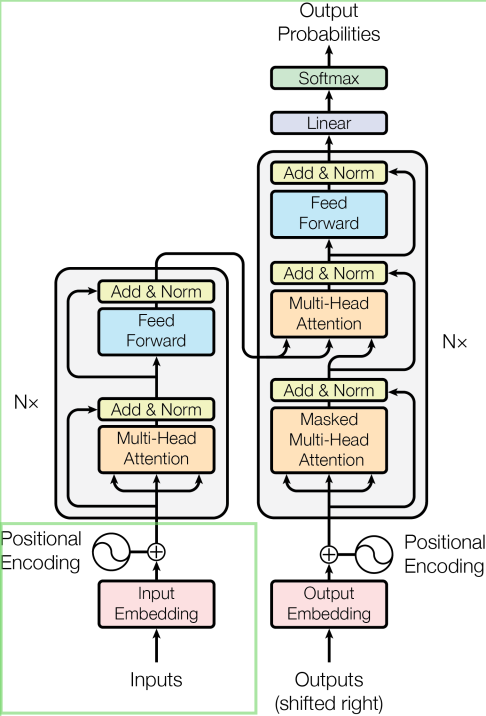
そして,単語の並びを事前に計算した後に,単語と単語の結びつきの強さを”Multi-Head Attention”を用いて総当りで一気に計算してしまう。このような並列計算はnVidiaなどが販売するGPUが最も得意とする計算分野です。
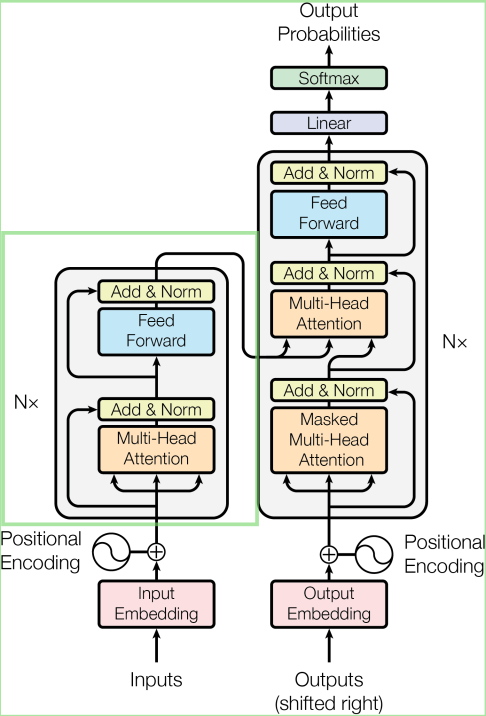
このようにすることで事前学習が2つのプロセスに分割され,圧倒的な効率で並列計算できるようになりました。
- 「単語の並び」は位置エンコーダー(Positional Encoding)で行列に格納
- 「単語間の結びつき」は多頭アテンション(Multi-Head Attention)で行列に格納。全単語総当りで学習させる。
この並列計算技術が登場したことでGPUが脚光を浴びることになります。GPUを増やせば増やすほど学習データを大量に短時間で処理することができるようになり,しかも確実にLLMが賢くなることが分かったからです。
これをスケーリング則といいます。
GPUはニューロンの化学反応そのもの
GPUのコアというのは整数計算機(INT32)・浮動小数計算機(FP32)といった計算機が数百個から数万個並べたもので構成されており,これをSM(ストリーミング・マルチプロセッサー)と呼びます。
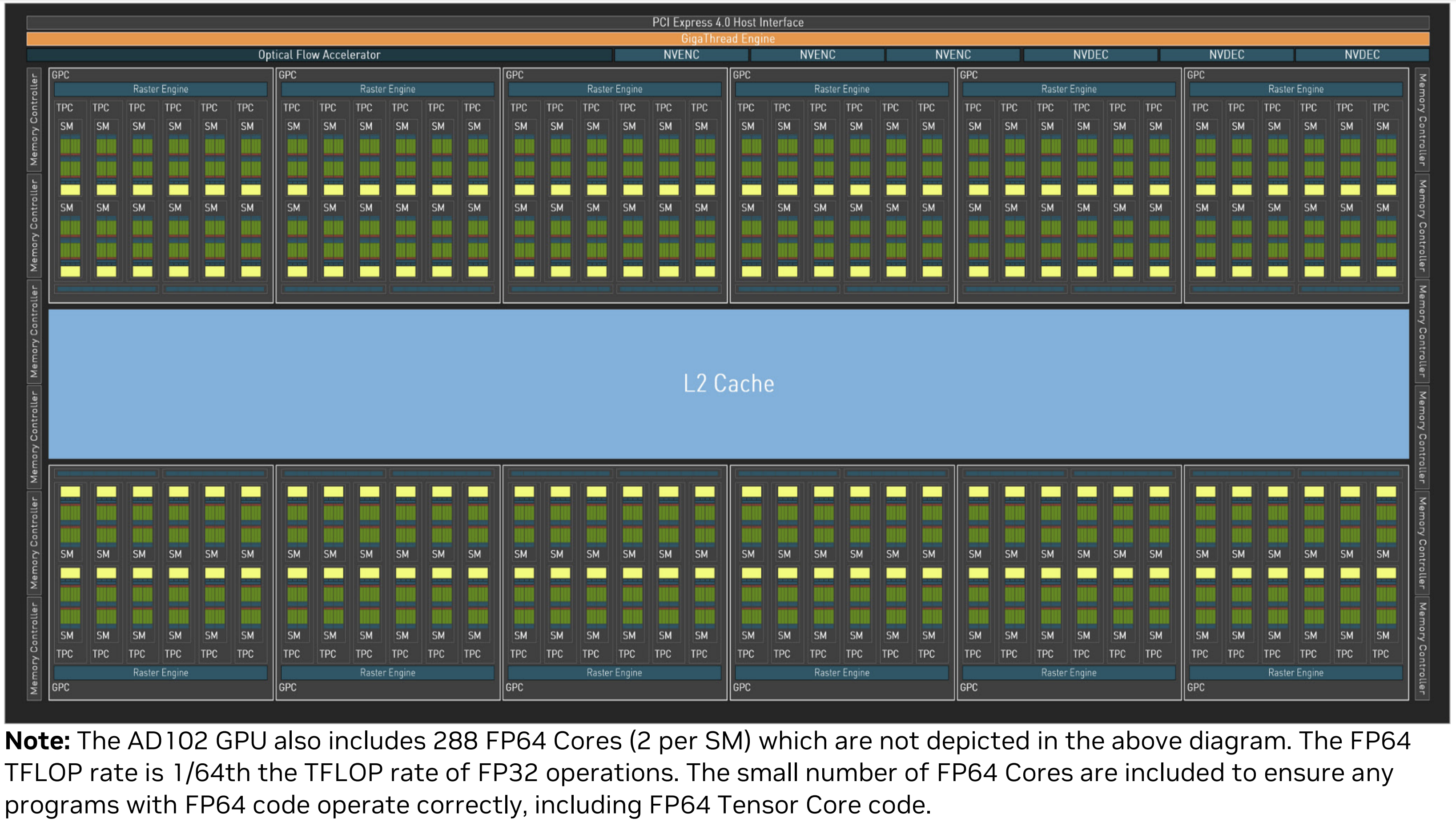
このGPUのコアの部分をさらに拡大したのが以下のようなグリッドです。 ADA LovelaceのAD102では下図のようなグリッドが最大12個搭載されています。

そしてこのグリッドの中にはさらにSM(ストリーミング・マルチプロセッサー)が12個搭載されています。そのためAD102では
12個のグリッド x 12個のSM = トータル144個のSM
もの並列計算機が搭載されていると言うことになります。
さらにこのSM(ストリーミング・マルチプロセッサー)の中には整数計算機・浮動小数計算機が並んでいます。
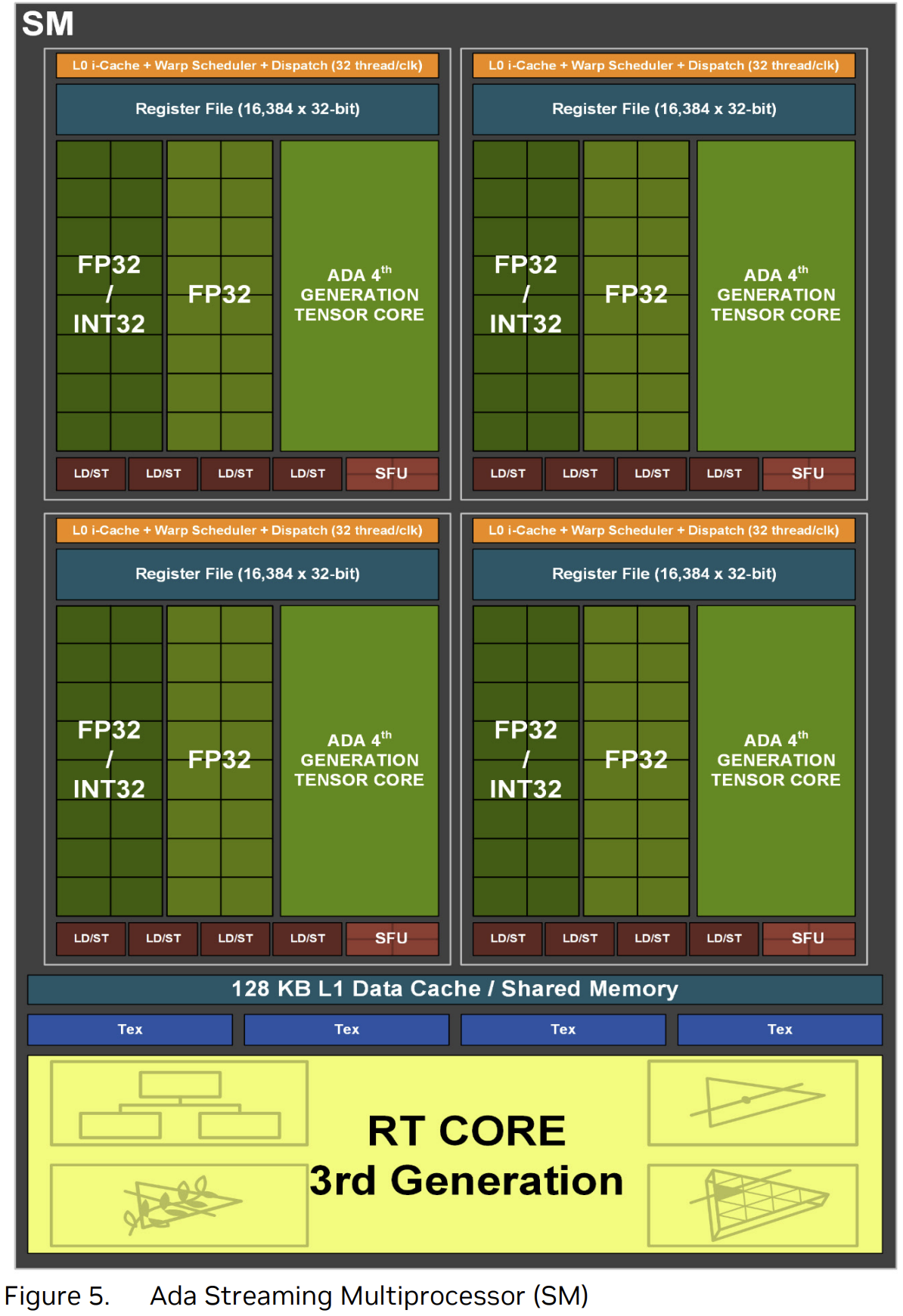
私も仕事柄GPUを用いて計算処理を行うことが多いのですが,このSMの密度の高さには驚かされました。最先端のCPUコアでも16コアや24コアが最多です。サーバー用途であれば64コアなどありますが。それらをさらに上回るコア数の計算機がnVidiaのGPUコアには搭載されています。
アテンション技術で思考・回答する
学習でアテンションを用いた計算手順については上記で解説しました。
さらにトランスフォーマーは思考・回答プロセスでも”Attention”技術を用いています。
まず,ユーザーからの入力単語を”Masked Multi-Head Attention”と呼ばれるアテンション処理で重み付けを行い,ユーザーがどういうリクエストを出しているのかを計算します。
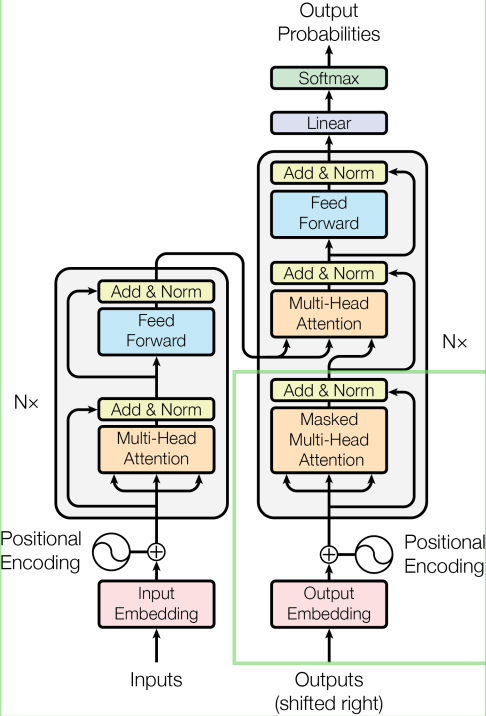
さらにこのユーザーからのリクエストと,事前学習データを入力として,もう一度”Multi-Head Attention”(3回目の登場)を行います。こうすることで,事前学習データとユーザー入力プロンプトの全てを加味して回答を生成します。
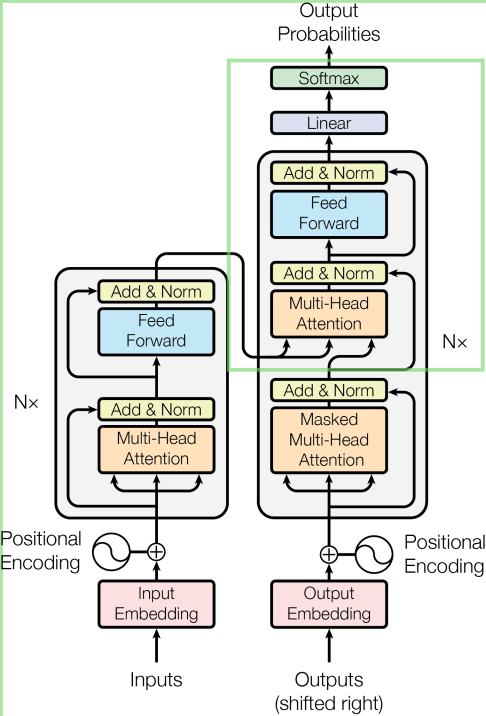
生成AIは人間の創作活動のモデル化
以上を整理すると
- 学習データの単語の並びを数値化: 位置エンコーダー(“Positional Encoding”)
- 学習データの単語の結びつきを数値化: “Self-Attention”
- 入力プロンプトの単語の並びを数値化: 位置エンコーダー(“Positional Encoding”)
- 入力プロンプトの単語の結びつきを数値化: “Masked Self-Attention”
- 学習データのアテンションと入力プロンプトのアテンションの両方を入力として単語間の結びつきを数値化: “Multi-Head Attension”
このような流れになります。
常に「単語の並び」と「単語間の結びつき」を個別に処理しているという点が一貫していますね。これは人間が試験勉強するのと,試験を実際に受けるプロセスに酷似しているのが解ると思います。
またトランスフォーマーの特色として,事前学習データの単語の並び・単語間の相関の強さ・入力プロンプトの内容把握といった要素すべてが「行列計算」で処理される点も特徴と言って良いでしょう。行列の計算はCPUにとっては負荷が大きいですが,GPUにとっては負荷は高くありません。GPUとはもともとグラッフィック計算に特化した計算ユニットであり,二次元や三次元の行列計算を並列で行うことに特化しています。
行列計算に特化したモデルとしてトランスフォーマーが登場し,さらにChatGPTやStable Diffusionなどのアプリケーションが2020年以降に公開されユーザー人口が激増したことで,nVidiaのGPUを使用したデータセンターへの投資が年率数倍ペースで拡大しています。このペースは当分はとどまることはないでしょう。
なぜかと言うとデータセンターに投資を行えば,現在はほぼ確実にLLMのモデルが賢くなることが分かっているからです。少なくとも過去7年間に渡っては計算資源の強化と投入するデータ量に比例して賢くなるという結果が続いており,今後もアルゴリズムの改良などによってこの傾向は続くと見られています。
LLMから人類の脳の仕組みを学ぶ
LLMは脳の模倣モデルとしては秀でており,思考回路アーキテクチャーとしては理にかなっています。また,人類はLLMの仕組みや思考プロセスを学ぶことで,人間の脳の働きを理解することにも繋がります。
トランスフォーマーは2017年に登場して以来7年間に渡ってトップランナー技術として君臨し続けていますが,モデルとしての完成度は非常に高く,想像以上に奥が深い技術です。